컴퓨터 메모리 시스템 가이드 (Memory System Guide)
컴퓨터의 메모리는 작업을 처리하기 위한 **’임시 작업 공간(Temporary Workspace)’**입니다. 최근에는 일반적인 **영상 편집(Video Editing)**을 넘어 로컬 AI(Local AI – LLM, 이미지 생성 등) 구동이 중요해지면서, 메모리 구조에 따른 성능 차이가 더욱 극명해지고 있습니다.
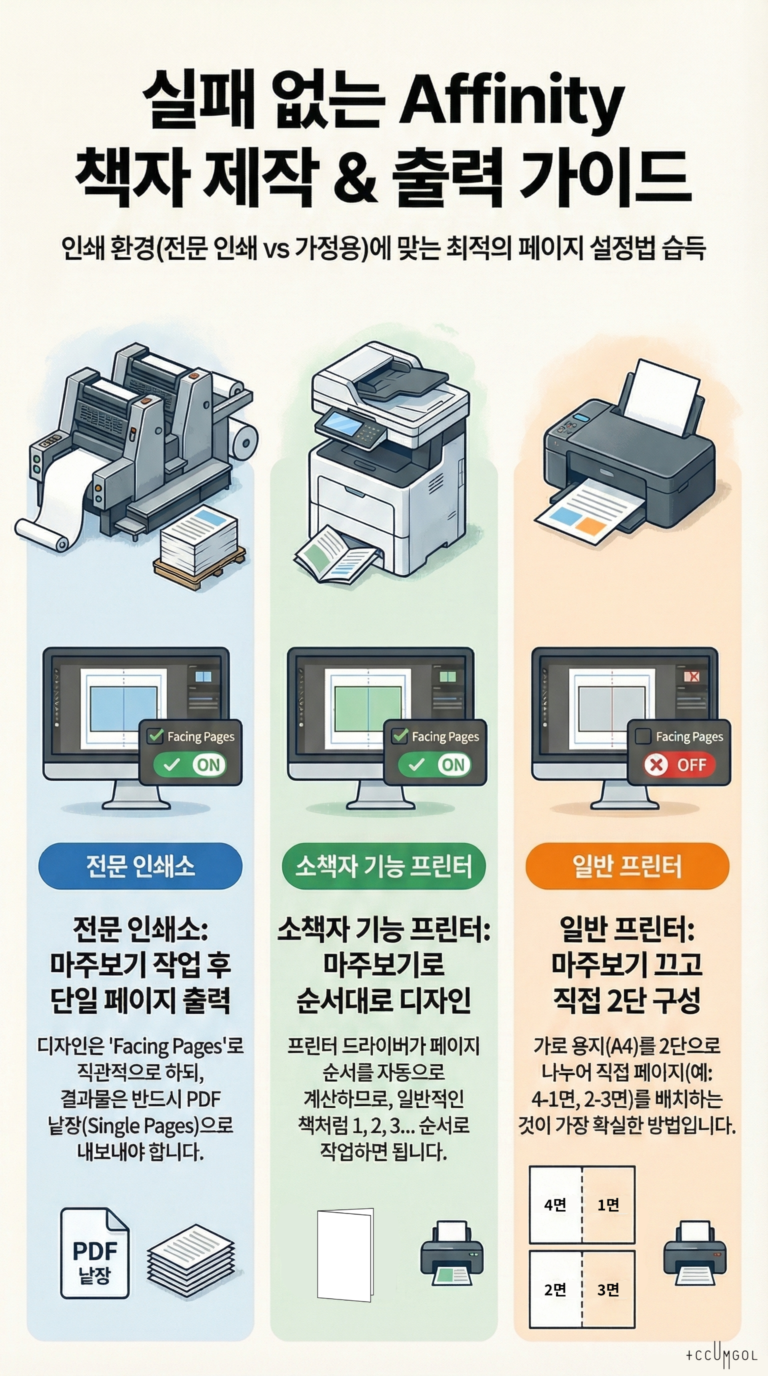
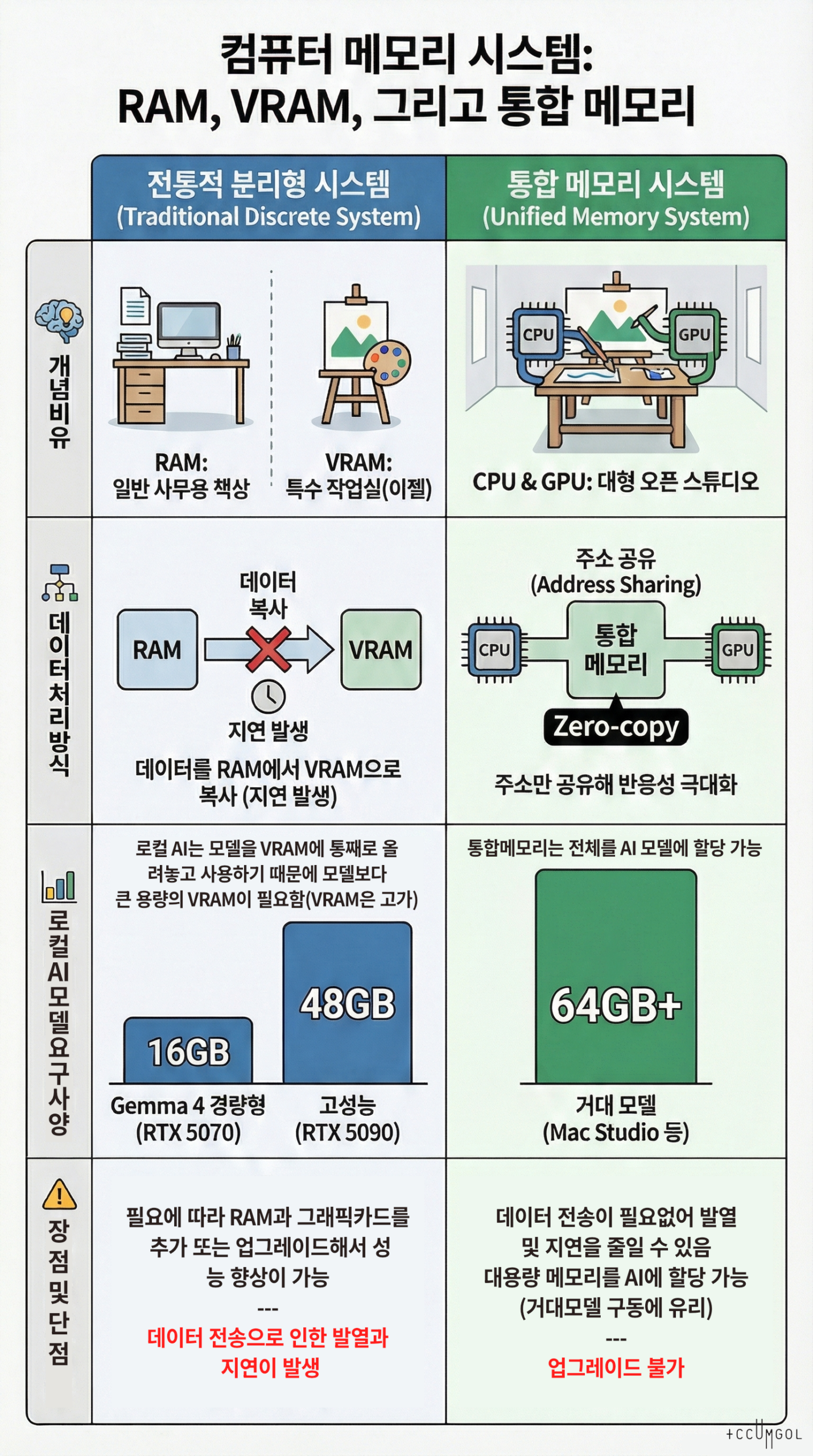
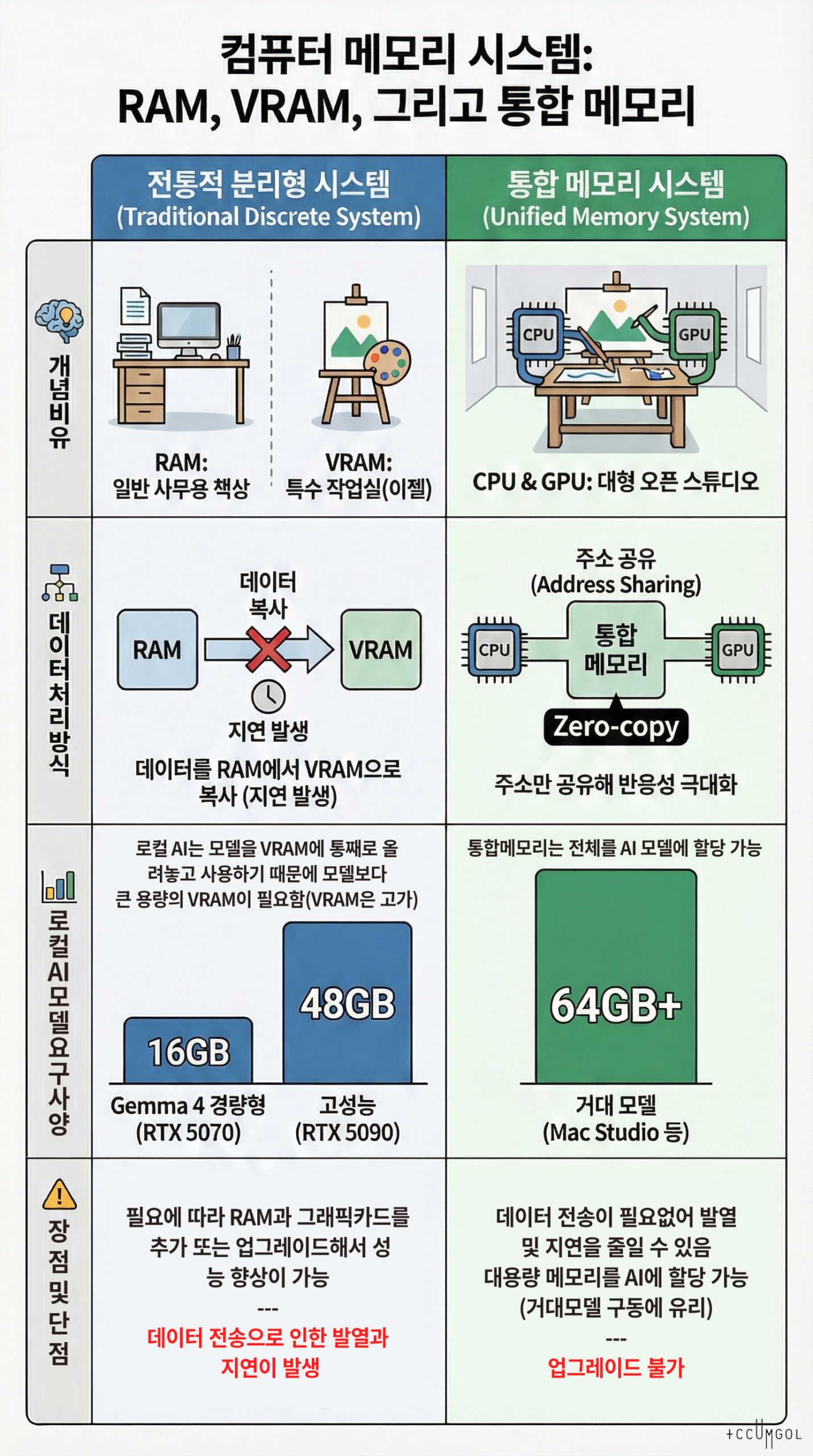
1. 메모리의 종류와 특징 (Types and Features)
| 종류 | 역할 | 실생활 비유 | 위치 |
| RAM | 일반적인 시스템 작업, 웹 브라우징, 프로그램 실행 등 | 사무용 책상 | 메인보드 슬롯 |
| VRAM | 그래픽 렌더링, 영상 출력, AI 모델 연산 전용 | 특수 작업실 (이젤) | 그래픽 카드 내부 |
| 통합 메모리 | CPU와 GPU가 경계 없이 함께 사용하는 고성능 메모리 | 대형 오픈 스튜디오 | 프로세서(SoC) 패키지 |
2. 작업별 처리 과정 비교 (Data Flow Comparison)

🎬 Case A: 일반 영상 편집 (Video Editing)
영상 편집은 데이터를 자주 읽고 쓰며, 효과를 입힐 때 CPU와 GPU 사이의 빠른 소통이 중요합니다.
- 전통적 시스템: 영상 소스를 RAM에 로드한 뒤, 색 보정 등을 위해 그래픽 카드로 데이터를 **복사(Copy)**해서 보냅니다. 이 복사 과정에서 미세한 끊김(Stuttering)이나 **지연(Latency)**이 발생할 수 있습니다.
- 통합 메모리: CPU가 컷 편집을 한 데이터의 메모리 주소를 GPU에게 바로 넘겨줍니다. **복사 과정이 생략(Zero-copy)**되므로 고화질 4K/8K 영상 프리뷰가 훨씬 매끄럽습니다.
🤖 Case B: 로컬 AI 작업 (Local AI / LLM / Stable Diffusion)
AI 작업은 수십억 개의 **매개변수(Weights/Parameters)**를 메모리에 ‘통째로 올려두고’ 계속해서 계산해야 합니다.
- 전통적 시스템: 반드시 AI 모델의 용량보다 큰 VRAM 용량이 필요합니다. 예를 들어 대용량 오픈소스 모델을 돌리려면 24GB 이상의 VRAM을 가진 고가의 그래픽 카드가 필수입니다. 일반 RAM이 아무리 많아도 VRAM이 부족하면 실행조차 안 되거나 속도가 수백 배 느려집니다.
- 통합 메모리: 시스템 메모리(예: 64GB, 128GB) 전체를 GPU가 사용할 수 있습니다. 따라서 수천만 원대 서버급 GPU에서나 돌아갈 법한 **거대 AI 모델(Large Models)**을 일반 노트북에서도 구동할 수 있는 혁신적인 환경을 제공합니다.
3. [2026.04 기준] 로컬 AI 모델과 하드웨어 매칭
AI 연산의 핵심은 **”데이터를 메모리에 가둬두고 빛의 속도로 계산하는 것”**입니다. 현재 가장 많이 쓰이는 모델과 필요한 사양은 다음과 같습니다.
▮ 주요 AI 모델별 권장 사양
- 경량형 및 에지 모델 (Gemma 4 E2B~E4B)
- 용량: 약 10GB~16GB VRAM (FP16 또는 고품질 양자화 기준)
- 권장 GPU: NVIDIA RTX 5070 (16GB) 또는 RTX 4070 Ti Super
- 예상 가격: 약 90만 원 ~ 120만 원대
- 범용 고성능 모델 (Gemma 4 26B MoE / ChatGPT OSS 20B)
- 용량: 약 24GB~48GB VRAM (추론 속도 및 컨텍스트 확보 기준)
- 권장 GPU: NVIDIA RTX 5090 (28GB~32GB 예상) 또는 RTX 4090
- 예상 가격: 약 280만 원 ~ 350만 원대 (단일 카드 기준)
- 전문가용 거대 모델 (Gemma 4 31B Dense 이상 / 대규모 에이전트 워크플로우)
- 용량: 64GB 이상의 메모리 상주 필요
- 권장 하드웨어: Mac Studio (통합 메모리 128GB 이상) 혹은 RTX 5090 듀얼(NVLink 대체 기술) 구성
- 예상 가격: 600만 원 이상
▮ 메모리 성능의 결정적 요소
- 용량의 벽(Capacity Barrier): 모델 파라미터가 VRAM을 넘어서는 순간 시스템은 마비됩니다. Gemma 4나 ChatGPT OSS 같은 최신 모델은 지능은 높지만 그만큼 메모리 점유율도 상당합니다.
- 병목 현상(Bottleneck): VRAM이 부족해 데이터가 일반 RAM으로 밀려나면 답변 속도가 초당 1~2토큰(단어) 수준으로 떨어져 실사용이 불가능해집니다.
- 통합 메모리의 강점: Mac의 통합 메모리는 대용량 모델 구동 시 그래픽 카드 수천만 원어치의 효율을 낼 수 있어 로컬 AI 연구자들에게 필수적인 선택지가 되었습니다.
4. 최종 비교 요약 (Summary Table)
| 구분 | 전통적 시스템 (RAM + VRAM 분리) | 통합 메모리 시스템 (UMA / Mac) |
| 영상 편집 | 그래픽 카드 성능에 따라 강력하지만 전송 지연 존재 | 컷 편집 및 고해상도 프리뷰에서 압도적 반응성 |
| 로컬 AI 작업 | VRAM 용량에 의한 제한이 매우 엄격함 (고가 장비 필요) | 대용량 메모리를 AI에 할당 가능하여 거대 모델 구동 유리 |
| 확장성(Scalability) | 필요할 때 램이나 GPU를 교체하여 성능 향상 가능 | 구매 후 업그레이드 불가 (초기 선택이 중요) |
| 추천 | 고사양 게임 유저, 하드웨어 DIY 선호자 | 영상 전문가, AI 개발자 및 연구자, 대학생 |
💡 결론 (Conclusion)
단순히 연산 속도만 본다면 하이엔드 외장 그래픽 카드가 빠를 수 있습니다. 하지만 Gemma 4나 ChatGPT OSS와 같은 로컬 AI 작업처럼 메모리 용량이 결정적인 영역에서는, 시스템 메모리를 VRAM처럼 통째로 빌려 쓸 수 있는 통합 메모리 시스템이 훨씬 더 넓은 확장성과 사용성을 제공합니다.