나홀로 완성한 ChurchWiki 지식 그래프 구축기 (1차 자료 입력 편)
아직 완성된 것은 아닙니다. 1자 자료(성경개요, 개역개정 성경본문, 성경 인명/지명 사전)만 입력된 상황입니다. 중간 결산의 의미를 담아 공유합니다.
1. 시작하며: 단순한 텍스트 파일들을 거대한 지식망으로
“수천 개의 성경 사전, 본문 텍스트들을 어떻게 하나로 연결할 수 있을까?”
이 작은 질문에서 모든 것이 시작되었습니다. 예전에는 폴더를 만들고 텍스트 파일을 복사해 넣는 것이 전부였지만, 이번에는 달랐습니다. 흩어져 있는 자료들이 서로 유기적으로 연결되는 ‘지식 그래프(Knowledge Graph)’를 만들고 싶었거든요. 이 글은 코딩 전문가가 아니어도, 든든한 AI 조력자들과 함께 수천 개의 데이터를 나만의 살아있는 위키로 만들어낸 좌충우돌 에피소드입니다.
2. 든든한 지원군들: 나의 작업 환경과 도구들
초보자도 무작정 따라 해 볼 수 있었던 이유는 복잡한 기술을 대신해 준 훌륭한 도구들과 든든한 조력자 덕분입니다.
2.1. 베이스캠프: Obsidian (옵시디언)
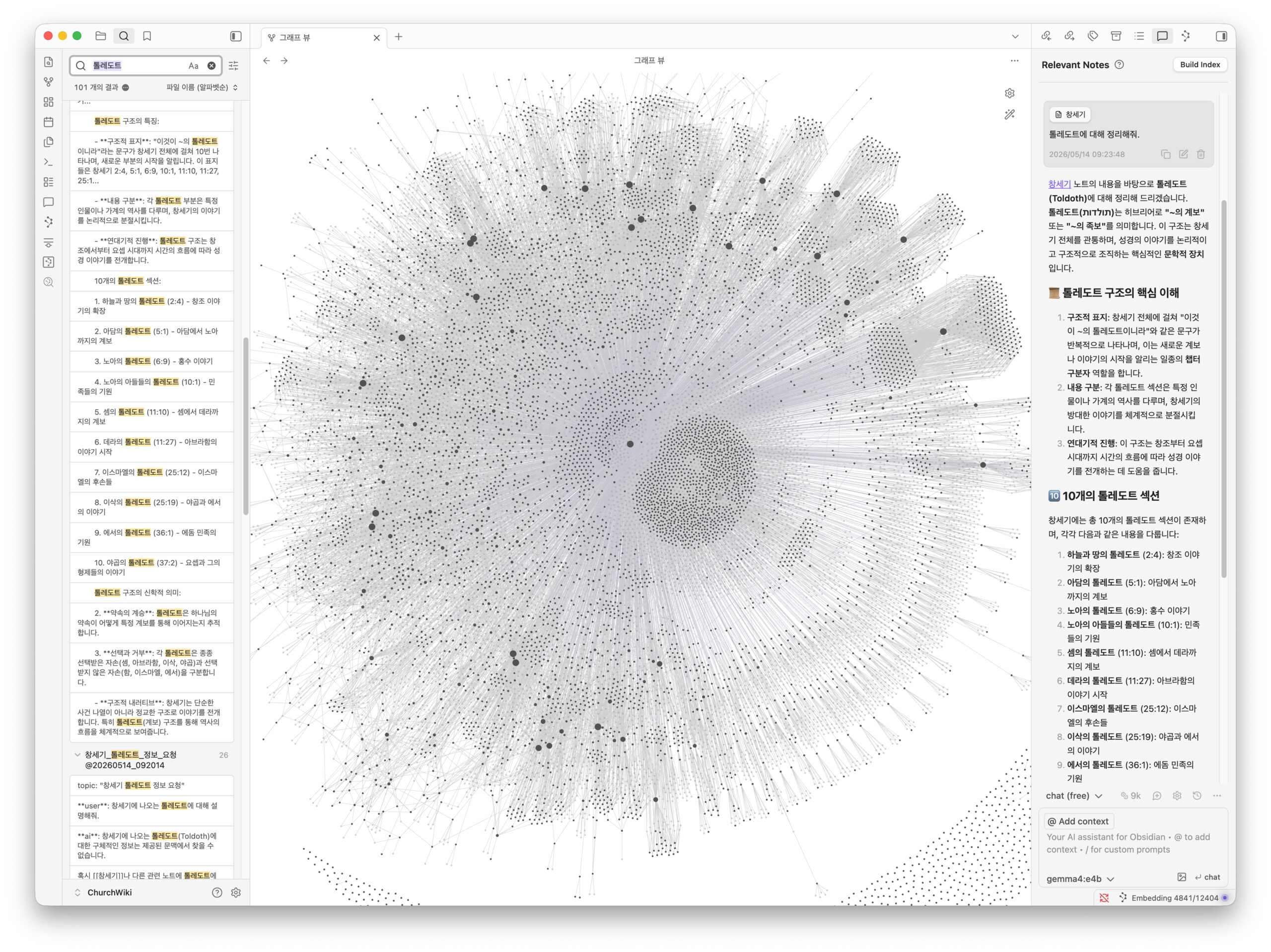
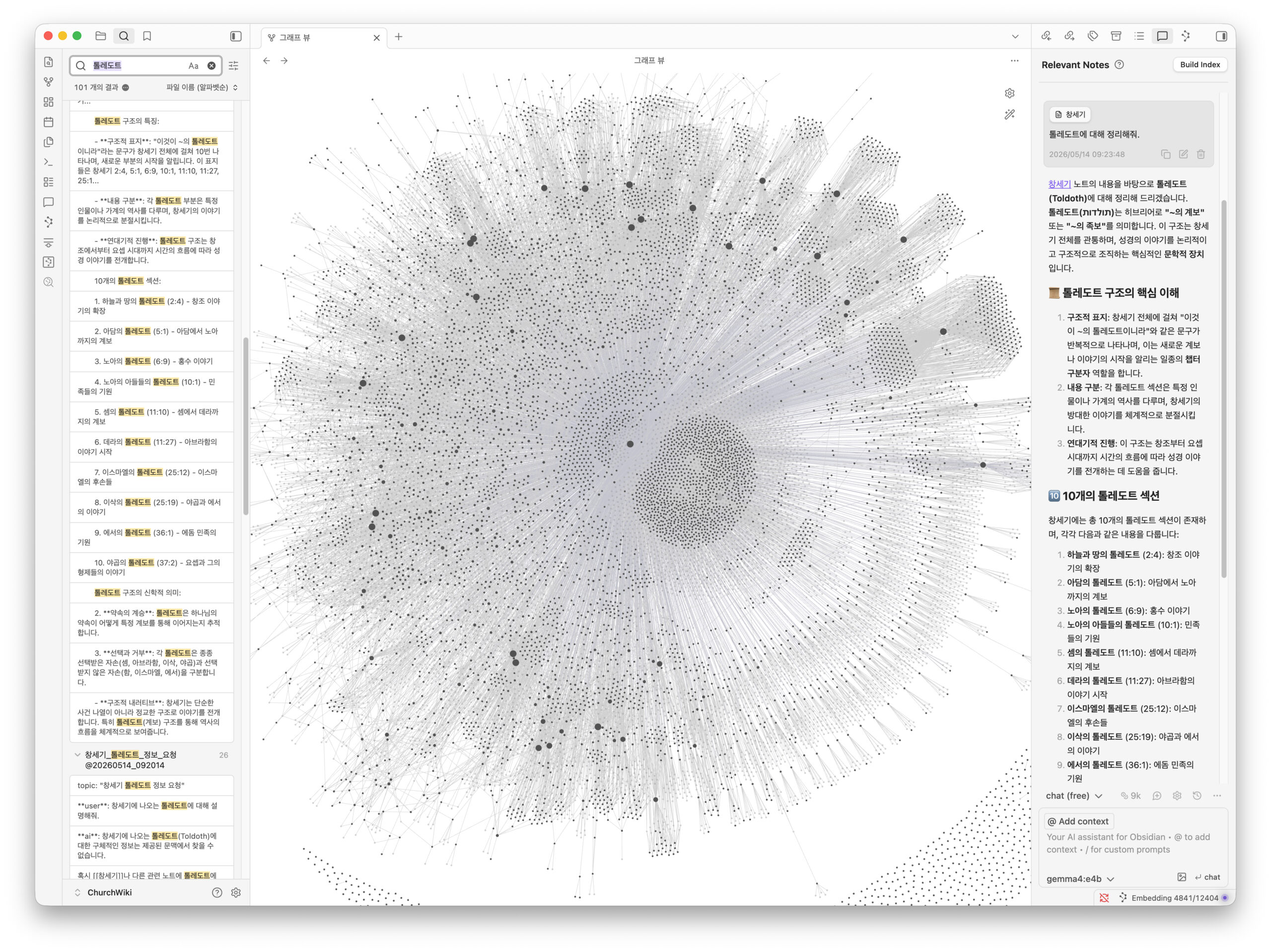
우리의 모든 자료가 모이는 예쁜 도서관입니다. 마크다운(Markdown)이라는 단순한 텍스트 형식으로 글을 쓰면, 옵시디언이 알아서 단어와 단어 사이의 연결 고리(Backlinks)를 시각적인 별자리(그래프)처럼 보여줍니다. 복잡한 데이터베이스 설정 없이 내 컴퓨터 폴더를 그대로 사용하기 때문에 가장 직관적이고 안전한 도구입니다.
2.2. 고민의 연속, 어떤 AI를 쓸 것인가? (Ollama의 선택)
가장 큰 난관은 수천 개의 텍스트를 읽고 ‘요약’과 ‘태그’를 달아주는 노동이었습니다.
처음에는 우리에게 친숙한 ChatGPT나 Claude 같은 클라우드 AI를 쓸까 고민했습니다. 하지만 천 개가 넘는 문서를 API로 처리하려다 보니 막대한 ‘비용 폭탄’이 걱정되었고, 중간에 호출 제한(Rate Limit)에 걸려 며칠 동안 작업이 마비될 게 뻔했습니다.
그래서 내린 결론이 제 맥북(M4 MacBook Pro)에서 오프라인으로 쌩쌩 돌아가는 Ollama(올라마)였습니다. 전기세 말고는 100% 무료인데다, 네트워크 제약 없이 무제한으로 돌릴 수 있었거든요! 모델은 한국어에 능통하고 속도가 빠른 qwen3:8b 모델을 선택해 제 컴퓨터를 훌륭한 무료 AI 서버로 변신시켰습니다.
- Model은 fast와 heavy 두가지 모드로 사용합니다. fast 모드는 qwen3:8b, heavy 모드는 gemma4:e4b입니다.
- 로컬 LLM을 사용하기 위해서는 컴퓨터의 VRAM이 중요합니다. 맥북은 Unified Memory를 사용하기 때문에 메모리 용량 자체가 로컬 LLM을 사용할 수 있는 용량이지만, 윈도우즈 컴퓨터의 경우 RAM이 아닌 비디오카드의 VRAM을 확인해야 합니다.
2.3. 나만의 전담 수석 엔지니어: Antigravity (AI 페어 프로그래머)
아무리 Ollama가 무료라지만, “파일을 읽어서 옵시디언으로 옮겨라”라고 명령하려면 누군가 파이썬 코드를 짜야 합니다. 저는 코딩에 머리를 싸매는 대신 Google의 Antigravity(앤티그래비티)라는 AI 코딩 어시스턴트를 수석 엔지니어로 고용했습니다.
“여기에 텍스트 파일들을 왕창 넣을 테니까, 네가 알아서 양식에 맞게 옵시디언으로 들어가게 해줘!”라고 말만 하면, Antigravity가 터미널을 열고 코드를 짜고, 폴더를 만들고, 에러가 나면 원인을 분석해 스스로 고쳤습니다. 저는 그저 아이디어를 내고 “좋아, 진행해”라며 모든 것을 조율하는 ‘감독’ 역할만 즐기면 되었습니다.
특히 원 자료를 입력하기 좋은 개별 자료로 분리하는 것도 Antigravity로 가능했습니다. 성경 전체 본문을 자료화하기 좋게 장별로 나눠서 개별 파일을 만드는 일은 수작업으로 하기에는 너무나 번거로운 작업인데, 개념만 설명하고 만들어 달라고 하면 만들어 주는 AI Agent 기능은 너무나 큰 도움이 되었습니다.
2.4. 발행을 도와준 도구: olw (Obsidian LLM Wiki)
AI가 작성해 준 초안(Draft) 문서를 검토하고, 옵시디언의 정식 위키 공간으로 보내주는(Publish) 깃허브 오픈소스 툴입니다. 복잡한 절차 없이 olw approve --all 이라는 마법의 주문 한 줄이면 수백 개의 문서가 내 위키로 정식 발행됩니다. 이 툴은 카파시가 제안한 gist를 다른 분이 패키지로 만들어 깃허브에 올려놓은 것을 내려받아 사용했습니다. 위에 설명한 것과 같은 명령어 셋들을 가지고 있어서 단순한 명령으로 여러 문서를 처리하는 작업이 가능합니다.
3. 우당탕탕 1차 입력 대작전 (에피소드로 보는 시행착오)
어렵고 복잡한 기술 이야기보다는, 저와 Antigravity가 어떻게 수천 개의 파일을 처리하며 위기를 넘겼는지 이야기해 볼게요.
😅 에피소드 1: “앗, AI가 뻗어버렸어요!” (과부하 사건)
테스트가 성공하자 신이 나서 raw/ 폴더에 1,000개가 넘는 성경 사전 파일을 냅다 던져 넣었습니다. “자, 일해라!” 하고 기다렸는데… 맙소사, 시스템이 AI에게 1,000개의 일을 동시에 시키려다 보니 로컬 서버가 감당하지 못하고 쓰러져 버렸습니다.
우리의 해결책: 수석 엔지니어 Antigravity가 즉각 나서서 “순차적 대기열(Batch Queue)”이라는 스크립트를 새로 짜주었습니다. 욕심부리지 않고 1번 문서의 요약이 완전히 끝나면 2번 문서를 먹여주는 식으로 속도를 조절했죠. 그랬더니 컴퓨터를 켜두기만 하면 며칠이고 쉬지 않고 묵묵히 일을 해내는 최고의 알바생이 탄생했습니다.
😡 에피소드 2: “콜론(:) 하나 때문에 전체 시스템이 마비되다니”
며칠 동안 AI가 열심히 만들어준 문서들을 기분 좋게 발행(olw approve) 하려는데, 갑자기 무시무시한 에러 메시지(ScannerError)가 뜨며 시스템이 멈췄습니다. 원인은 허무하게도 AI가 제목을 이쁘게 꾸민다고 중간에 넣은 ‘콜론(:)’ 기호 하나 때문이었습니다. 이 기호 하나 때문에 옵시디언이 문서를 읽지 못하고 토해낸 것입니다.
우리의 해결책: 멘붕에 빠진 저를 대신해 Antigravity가 나섰습니다. “앞으로는 제목에 무조건 쌍따옴표를 씌워서 오해를 없애자”는 규칙을 스크립트에 강제했습니다. 그리고 이미 망가져 버린 수백 개의 파일들도 단숨에 치료해 주는 마법 같은 복구 프로그램을 만들어 위기를 넘겼습니다.
😵💫 에피소드 3: “왜 자꾸 영어로 나오지?”(한글 자료와 영어 자료의 혼동)
설정에 모든 문서는 한글로 작성하라고 해놓았음에도 불구하고 중간 결과물(draft)이 자꾸 영어로 나오는 일들이 발생했습니다. 이 문제를 해결하기 위해 여러번 검색을 반복하면서 로컬 LLM을 이것 저것 바꿔보기도 했습니다. 고성능을 지향하는 보다 용량이 큰 모델도 사용해보고, Mistral도 시도해 보았습니다. 그런데, 어이없게도 원문 자료(raw) 문서 내용에 영어가 어느 정도 들어가 있으면 로컬 LLM이 문서를 영어로 작성해도 된다고 인식한다는 것이었습니다. 결국 ‘개역개정’과 ‘ESV’ 버전을 함께 한 파일에 넣었던 것을 다시 별도로 분리하여 한글 개역개정만 넣은 문서로 작업하게 되었습니다. 이것 때문에 로컬 LLM을 몇 번 바꾸고, 전체 프로젝트를 두 세 번 뒤집는 일이 있었습니다. 먼저 한글 자료를 최대한 넣은 후 추후에 영어 자료를 추가할 계획입니다.
🧐 에피소드 4: “도대체 어떤 스가랴입니까?” (동명이인과 폴더의 늪)
성경에는 ‘스가랴’나 ‘마리아’처럼 동명이인이 너무 많았습니다. A라는 스가랴 문서를 눌렀는데 B 스가랴 내용이 나오는 등 링크들이 뒤엉키기 시작했죠. 게다가 문서를 잘 정리해 보겠다고 ‘위키 > 성경사전 > 지명’ 식으로 폴더를 깊게 파두었더니, 정작 옵시디언 파일 트리에서 한눈에 문서를 찾기가 너무 힘들었습니다.
우리의 해결책: 동명이인들을 한데 모아주는 스가랴-통합.md 같은 ‘정거장(허브)’ 문서를 만들었습니다. 모든 스가랴 링크는 이 정거장으로 모인 뒤, 각자의 진짜 문서로 안내되도록 지식 그래프를 우아하게 다듬었습니다. 또한 복잡한 하위 폴더들을 싹 지워버리고 모든 문서를 루트 폴더로 꺼내는(플랫 구조) 과감한 결정을 했습니다. 그제야 복잡했던 지식 그래프가 깔끔하고 아름답게 그려지기 시작했습니다.
4. 마치며: 누구나 나만의 위키를 가질 수 있다
전문적인 코딩 기술을 몰라도 괜찮습니다. Antigravity 같은 똑똑한 AI 조력자와 약간의 인내심, 그리고 아이디어만 있다면 충분합니다. 내 컴퓨터 어딘가에서 잠자고 있던 수많은 단순 텍스트 쪼가리들을, 살아 숨 쉬며 서로 대화하는 나만의 거대한 지식 사전으로 탈바꿈시켜 보세요. 이 여정은 초보자 누구에게나 도전해 볼 만한 충분한 가치가 있습니다!