🧩
이 문서는 온톨로지(Ontology)를 처음 접하는 사람부터 실무 적용을 고민하는 팀까지 참고할 수 있도록, 정의부터 구축 방법까지 한 번에 정리한 개요입니다.
1) 온톨로지란 무엇인가
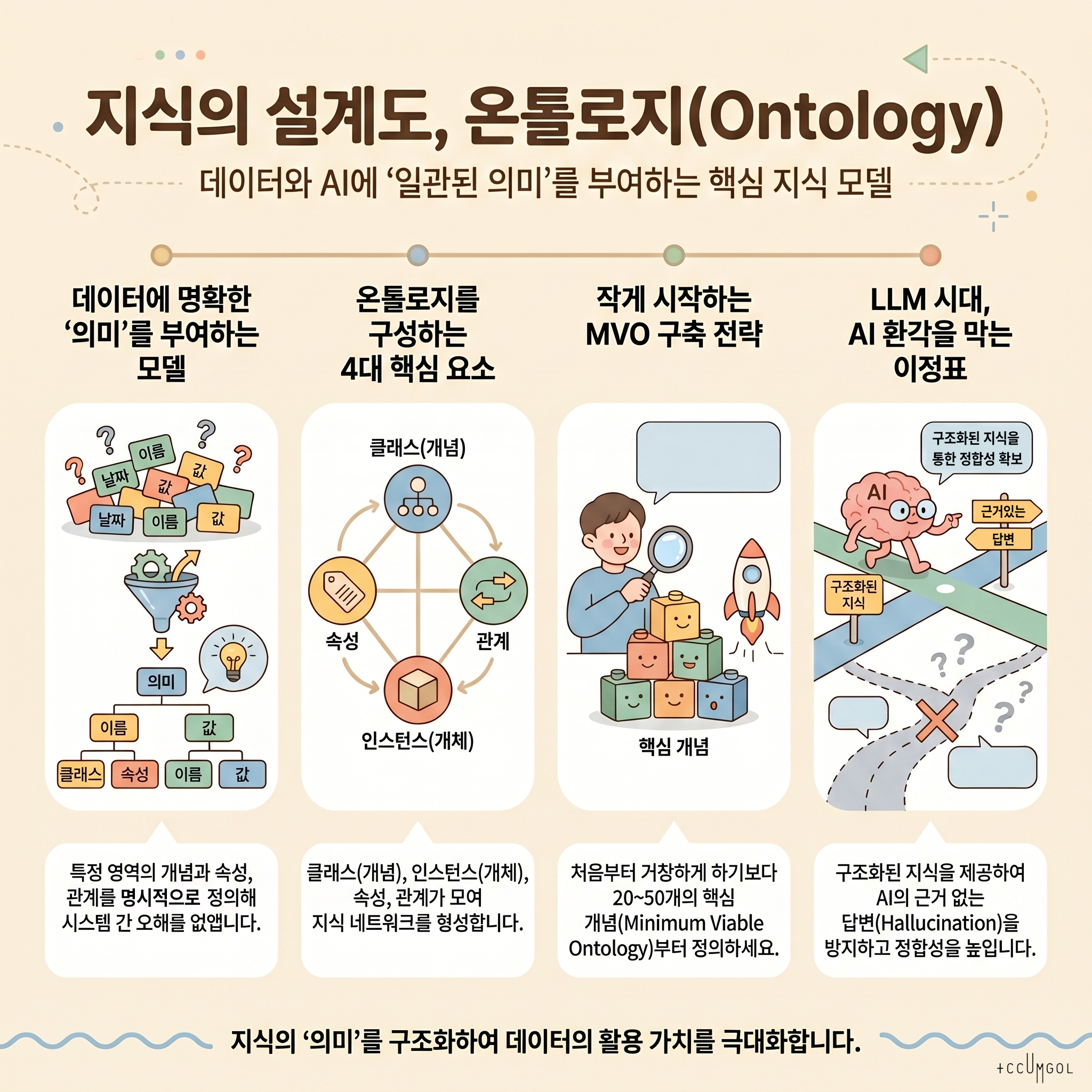
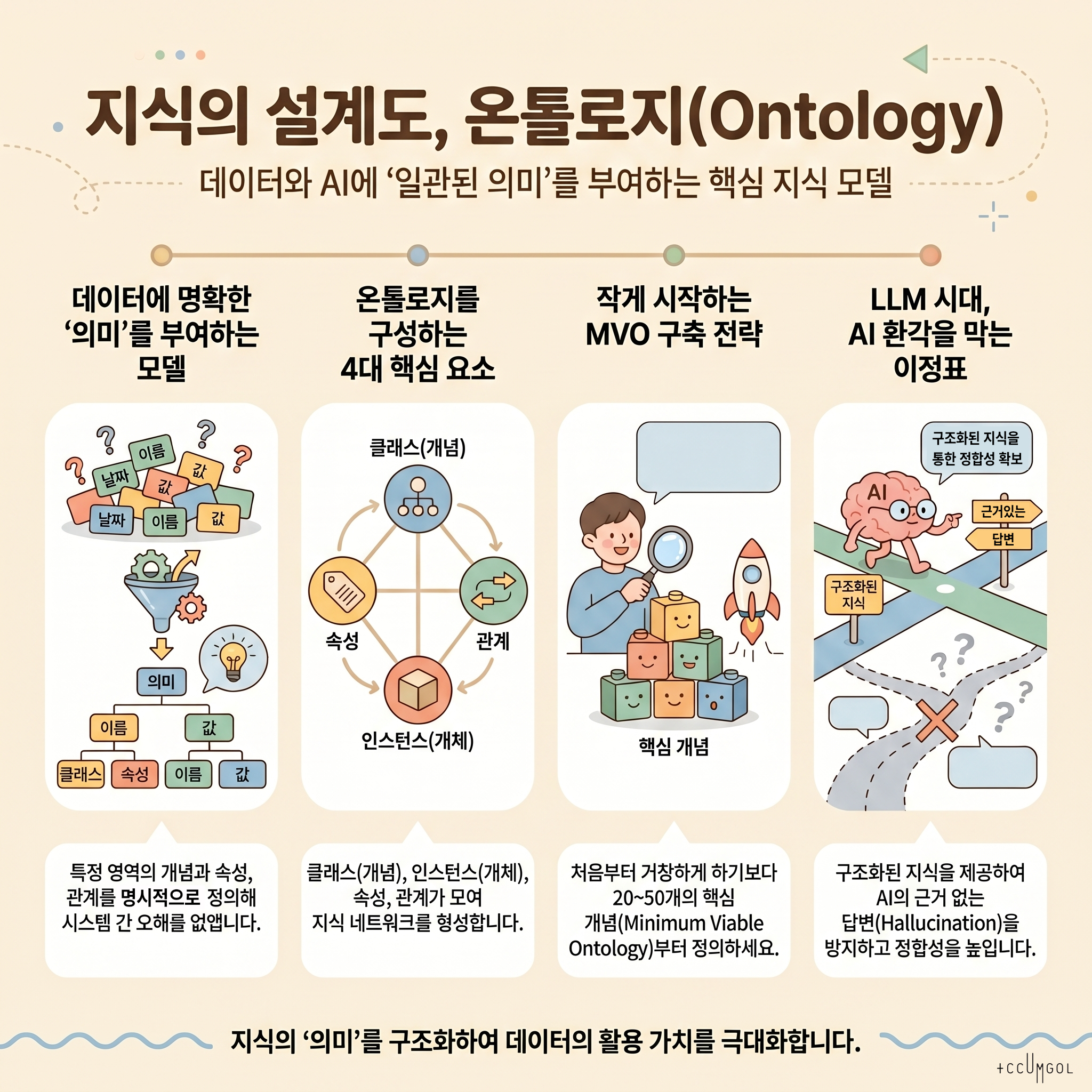
- 정의(한 문장): 온톨로지는 특정 도메인에서 중요한 개념(Entities), 그 속성(Properties), 개념들 사이의 관계(Relations), 그리고 이를 해석하는 규칙/제약(Constraints)을 명시적으로 표현한 지식 모델입니다.
- 핵심 목적: 사람과 시스템이 같은 단어를 써도 의미가 다르게 해석되는 문제를 줄이고, 데이터·문서·시스템 전반에서 의미(semantic)를 일관되게 공유하게 하는 것입니다.
2) 개념: 온톨로지는 무엇을 포함하나
- 클래스(Class)/개념: 예:
제품,고객,주문,질병,약물 - 인스턴스(Instance)/개별 개체: 예:
고객: 홍길동,제품: A모델 - 속성(Property): 예:
제품.가격,고객.거주지,주문.주문일 - 관계(Relation): 예:
고객-주문한다-주문,약물-치료한다-질병 - 계층 구조(Taxonomy): 예:
상품 > 전자제품 > 스마트폰 - 제약/규칙(Axioms/Constraints): 예: “주문은 반드시 1명 이상의 고객과 연결된다”, “직원은 동시에 퇴사 상태일 수 없다”
3) 온톨로지 vs 용어집/분류체계/지식그래프
- 용어집(Glossary): 용어의 정의를 모읍니다. 관계/규칙 표현은 제한적입니다.
- 분류체계(Taxonomy): 상하위(부모-자식) 중심 구조입니다. 관계 유형이 단순합니다.
- 온톨로지: 다양한 관계(원인-결과, 소속, 사용, 대체, 동의어 등)와 규칙까지 포함하는 의미 모델입니다.
- 지식그래프(Knowledge Graph): 온톨로지(스키마) + 실제 데이터(인스턴스)를 그래프 형태로 연결한 지식 네트워크로 이해하면 실무적으로 명확합니다.
4) 역사: 어디서 왔고 어떻게 발전했나
- 철학적 기원: “존재(being)란 무엇인가”를 다루는 형이상학 전통에서 ‘Ontology’라는 용어가 출발했습니다.
- AI/지식표현(1980~1990s): 전문가시스템과 지식표현 연구에서 ‘공유 가능한 개념 모델’의 필요가 커졌습니다.
- 시맨틱 웹(1990s~2000s): 웹 상의 데이터를 기계가 이해하도록 하자는 흐름에서 RDF/OWL 같은 표준이 등장하며 ‘온톨로지’가 기술적으로 정착했습니다.
- 엔터프라이즈/데이터 통합(2010s~): 데이터 레이크/웨어하우스가 커질수록 의미 불일치가 커져 도메인 온톨로지가 재조명되었습니다.
- LLM 시대(2020s~): 모델이 자연어를 다루는 능력은 커졌지만, “정확한 의미/정합성/근거”를 담보하기 위해 구조화된 지식(온톨로지)이 다시 중요해졌습니다.
5) 요즘 특히 주목받는 이유
- 데이터가 많아질수록 ‘의미 정렬’이 어려워짐: 부서별로 같은 용어를 다르게 쓰는 문제가 비용과 오류를 키웁니다.
- AI/검색/추천 품질 향상: 키워드 매칭이 아니라 의미 기반 검색(예: 동의어, 상하위, 관련 개념)으로 성능이 올라갑니다.
- LLM의 한계 보완(환각/일관성/감사 가능성): 온톨로지는 “무엇이 사실로 간주되는지”를 명시해 검증 가능한 기준점을 제공합니다.
- 규제·리스크 관리: 금융/의료/제조 등에서 데이터 정의와 관계가 명확해야 추적·감사·설명이 가능합니다.
- 시스템 통합과 M&A: 서로 다른 시스템의 필드/코드/정의를 온톨로지로 매핑하면 통합 비용을 낮출 수 있습니다.
6) 구축 접근법(개인/팀/기업 공통 프레임)
온톨로지는 한 번에 완성하기보다 작게 시작해 반복적으로 확장하는 편이 성공 확률이 높습니다.
A. 범위와 목적을 먼저 고정하기
- 어떤 문제를 풀 것인지 정합니다.
- 예: “문서 검색 정확도 개선”, “데이터 용어 통일”, “고객 360 통합”, “업무 규칙 검증”
- 도메인 경계를 정합니다.
- 예: ‘고객’은 마케팅 고객만 포함인지, 계약 주체까지 포함인지
B. 개념 후보 수집(소스 기반)
- 데이터 스키마: DB 테이블, 컬럼, 코드 값
- 문서: 정책/매뉴얼, 계약서, 보고서
- 업무 프로세스: 실제 화면/입력 폼/승인 흐름
- 현업 인터뷰: “그 단어를 언제 쓰고, 무엇을 포함/제외하나?”
C. 최소 온톨로지(MVO: Minimum Viable Ontology) 설계
- 핵심 20~50개 개념만 먼저 정의합니다.
- 각 개념에 대해 최소한 아래를 채웁니다.
- 정의(문장)
- 포함/제외 기준
- 대표 속성 3~10개
- 핵심 관계 2~5개
- 예시(인스턴스)
D. 관계·규칙을 ‘실용적으로’ 추가
- 관계 유형을 과도하게 늘리면 운영이 어려워집니다.
- 먼저 자주 쓰는 것부터:
- 상하위(is-a)
- 부분-전체(part-of)
- 소속/보유(has-a)
- 동일/동의어(equivalent/synonym)
- 참조/연결(related-to)
- 규칙은 “검증/자동화 이득이 큰 것”부터:
- 필수 관계, 카디널리티(1:N), 상태 전이 규칙 등
E. 매핑과 적용(가치가 발생하는 지점에 연결)
- 데이터 매핑: 각 개념·속성이 어떤 시스템 필드에 대응되는지 연결
- 문서 태깅/분류: 문서가 어떤 개념을 다루는지 연결
- 검색/QA: 온톨로지 기반으로 질의 확장(동의어, 상하위)
- 대시보드/지표: 지표 정의를 온톨로지의 개념·관계로 고정
F. 거버넌스(운영 체계)
- 온톨로지는 ‘데이터 제품’처럼 운영해야 지속됩니다.
- 추천 운영 요소:
- 변경 요청 프로세스(제안 → 검토 → 승인 → 배포)
- 용어 책임자(도메인 오너) 지정
- 버전 관리와 변경 로그
- 품질 기준(중복 개념, 정의 누락, 관계 충돌)
7) 개인이 구축하는 방법(간단하고 효과적인 방식)
- 목표 예시: “내 노트/자료를 의미 기반으로 다시 찾기”, “지식 영역 정리”
- 추천 단계:
- 큰 영역 5~10개(상위 개념)를 만듭니다.
- 각 영역에 핵심 개념을 카드처럼 정리합니다.
- 개념 간 관계를 2~3가지 타입으로만 연결합니다.
- 예: ‘관련 있음’, ‘원인’, ‘대비’
- 새 자료를 추가할 때마다 “어떤 개념에 속하는가, 무엇과 연결되는가”만 기록합니다.
- 팁: 처음부터 완벽한 계층을 만들기보다, 자주 찾는 것부터 정의하면 유지가 쉽습니다.
8) 기업이 구축하는 방법(실무 로드맵)
1단계: 파일럿(4~8주)
- 범위: 한 도메인, 한 유스케이스(예: 고객/상품/주문 중 하나)
- 산출물: 용어 정의서 + 최소 온톨로지 + 1~2개 시스템 매핑
- 성공 지표: 검색 정확도, 중복 지표 감소, 통합 매핑 시간 단축 등
2단계: 확장(2~6개월)
- 다른 도메인으로 확장하면서 상위 공통 개념(예: 조직, 사람, 계약, 이벤트)을 정리
- 데이터 카탈로그/거버넌스와 연결
3단계: 운영(지속)
- 변경 요청과 승인 흐름 정착
- 신규 시스템/지표/문서가 생길 때 온톨로지에 반영되도록 “업무에 끼워 넣기”
9) 자주 실패하는 지점과 예방책
- 너무 큰 범위로 시작: → 한 유스케이스로 시작하고 MVO로 제한
- 현업 정의 없이 기술만 도입: → 정의/포함기준/예시가 먼저
- 관계/규칙 과도 설계: → 가치가 있는 규칙부터 단계적으로
- 운영 부재: → 오너, 변경 절차, 버전 관리 필수
10) 다음에 구체화하면 좋은 질문(선택)
- 온톨로지를 어디에 쓰려 하나요. 검색, 데이터 통합, LLM 기반 QA 중 무엇이 우선인가요.
- ‘온톨로지로 합의해야 하는 핵심 용어’는 무엇인가요. 예를 들면 고객, 사용자, 회원 같은 단어입니다.
- 현재 가장 큰 혼란이 생기는 지점은 어디인가요. 문서, 지표, 코드, 시스템 간 매핑 중 무엇인가요.